Den Intelligente Patientjournal
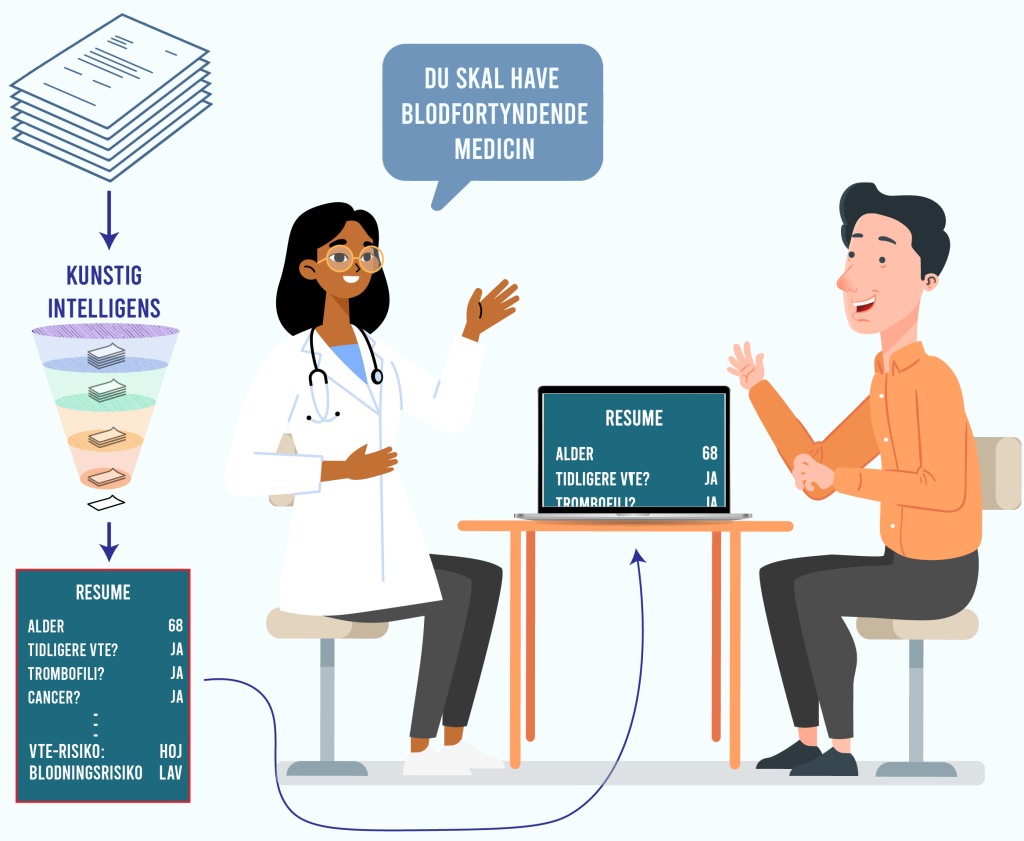
Kunstig intelligens hjælper sundhedspersonale
IPJ udvikler, implementerer og evaluerer algoritmer og klinisk beslutningsstøtte til medicinske beslutninger.
Visionen med dette forskningsnetværk er at skabe innovation, der kan hjælpe sundhedsvæsenet. Dette skal forbedre og lette arbejdsgange og skabe gode og sikre patientforløb.
Inden for sundhedsinnovation er det afgørende at kombinere teknologisk ekspertise med klinisk forståelse, så løsningerne ikke blot er teknisk gode, men også praktisk anvendelige og skaber reel værdi for patienter og sundhedsprofessionelle.
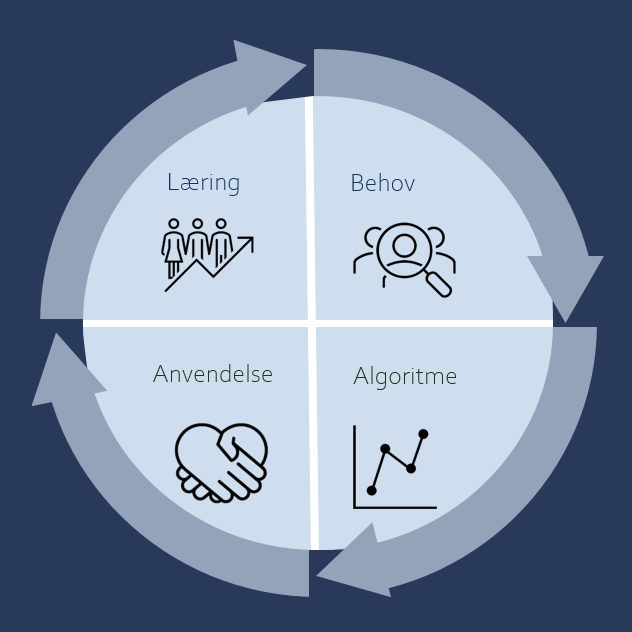
Bedre medicinske beslutninger
Fra Data til Sundhed
IPJ udvikler algoritmer til klinisk beslutningsstøtte – fra teknisk udvikling til implementering og evaluering.
Vores algoritmer omsætter sundhedsdata til præcis og brugbar indsigt, der understøtter hurtige og sikre medicinske beslutninger.
Med tværfaglig ekspertise, kvalitetsdata og et etisk fokus sikrer vi patientsikre og effektive løsninger, der kan anvendes bredt i sundhedsvæsenet.
Læs mere om projekterne her:
Samarbejdspartnere
